







SeeD is perhaps the most comprehensive genebank-characterization effort globally to this date. We are going to characterize the genetic makeup of up to 200,000 DNA samples from genebank accessions and introgression populations/lines. We will also characterize accession subsets of varying size and composition for a set of priority traits and breeding targets.

MIGUEL Borja Celio of CIMMYT captures field data, using SeeDB platform software on a portable device. ©2012 (CIMMYT)
Such an ambitious project would be impossible without a solid foundation in two key enabling technology areas:
- A robust, high-throughput genome-
profiling platform that accurately characterizes unknown genetic diversity, is ‘forward compatible’ with evolving genotyping technologies, and enables the standardized analysis of accessions from different genebanks at different times.
- A state-of-the-art software platform to collect, standardize, store, query, visualize, and analyze the ‘tsunami’ of data we expect SeeD participants to generate – ideally made of modules that can be repackaged so that SeeD clients can install and use these software tools themselves to more effectively utilize SeeD data.

Mexican scientists, trained for six months each, in sequencing genotyping technologies at DArT, Australia, before working at SAGA. From the left side to the right: Manuel Martínez, (Peter Wenzl, leader of SeeD), Hector Gálvez, Gerardo Gallegos and Aleyda Sierra. © 2012 (CIMMYT)
Given the critical nature of these enabling technologies, we have formed strategic partnerships with two organizations that have a proven track record of delivering solutions that are being readily adopted by their clientele, Diversity Arrays Technology (DArT) and the bioinformatics group at the James Hutton Institute (JHI).
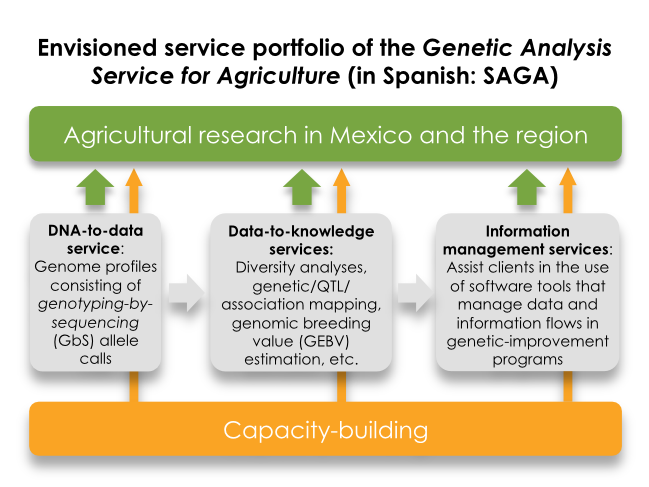
The primary objective of our partnership with DArT is to establish and operate a joint Genetic Analysis Service (SAGA for its Spanish acronym: Servicio de Análisis Genético para la Agricultura) at the National Center for Genetic Resources (CNRG). SAGA will initially focus on analyzing DNA samples for SeeD and other MasAgro components, using genotyping-by-sequencing (GBS) technologies, while simultaneously building capacities in configuring modern genomics tools to fit applications in demand-driven agricultural research. In the medium term, we envision that SAGA operations should become self-sustaining to support applied agricultural research in Mexico and the region beyond the duration of the SeeD project and the crops targeted by SeeD by offering a combination of genetic-analysis and value-adding information-management services.
{kind=link}
Information management presents a serious challenge for a project like

Building for visitors to the New National Center for Genetic Resources (CNGR) in Tepatitlán, near the city of Guadalajara. The CNRG has become the largest genetic resource center in Latin America. © 2012 (CIMMYT)
SeeD. We are working with both DArT and JHI to co-develop a modular software platform for the SeeD project (‘SeeDB‘ for ‘SeeD database’).
The entire SeeDB platform, including all its components and modules (for example for field data collection, will be made available for free. The code will be released under an Open Source license, starting with the first production version.
Project participants have developed a number of publicly available resources to facilitate the visualization and analysis of data.
| Resource | Provider | Functionality | Overview | Download |
| Flapjack | JHI | Genotypic data visualization | Overview | Download |
| CurlyWhirly | JHI | PCA analysis visualization | Overview | Download |
| Helium | JHI | Pedigree and characterization data visualization | Overview | Download |
| Strudel | JHI | Genetic and physical maps visualization | Overview | Download |
| Tablet | JHI | Next gen sequence data visualization | Overview | Download |
| Humbug | JHI | Barcode generation | Overview | Download |
| Germinate | JHI | Phenotypic, genotypic, climate, and passport data storage and visualization | Overview | Download |
| Germinate 3 Data Importer | JHI | Data import into Germinate 3 | Overview | Download |
| META-R – 3.5.1 | CIMMYT | R programs for statistical analyses relevant to breeding | Overview | Download |
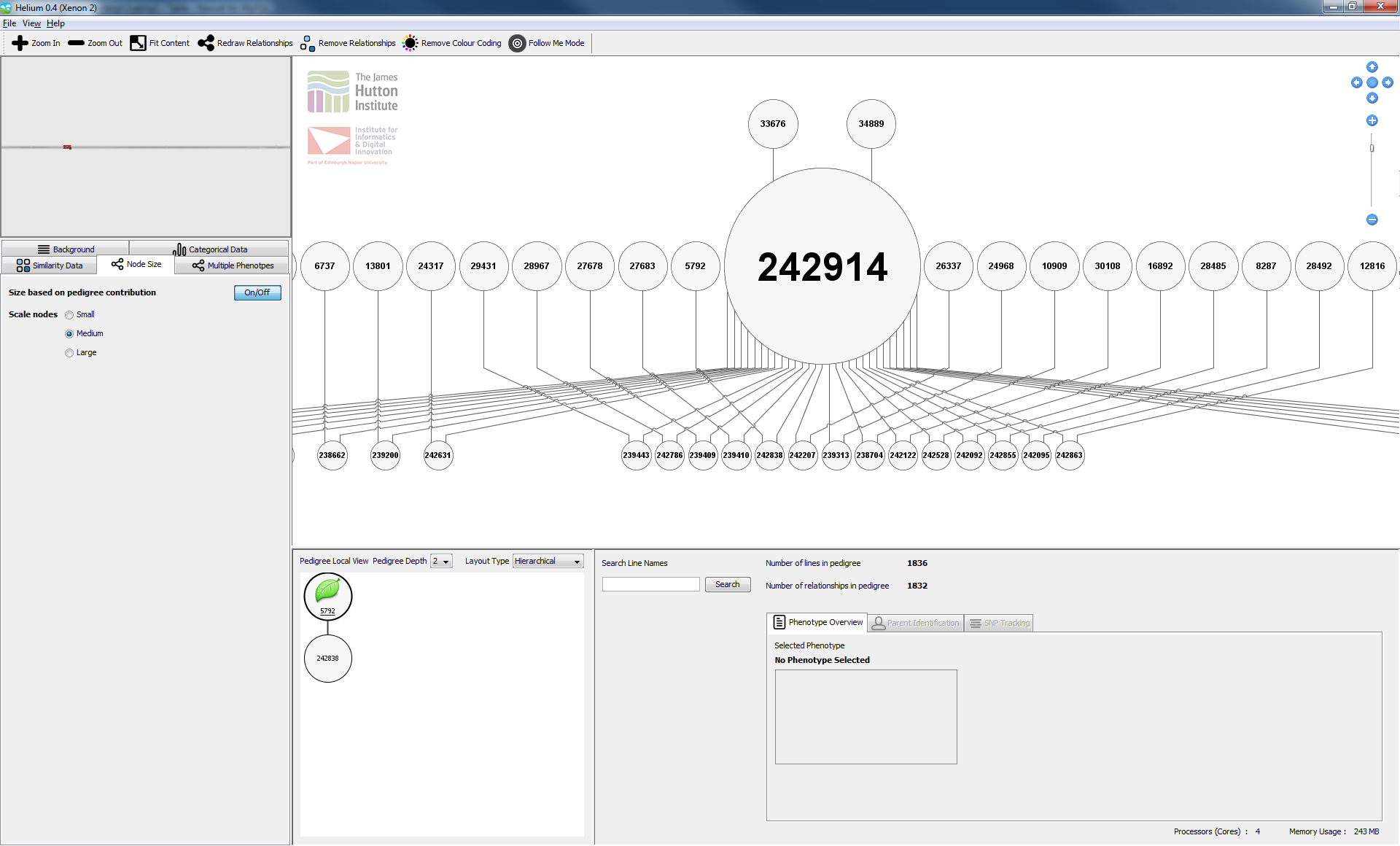
Helium is an example of a useful visualization tool developed by SeeD collaborators that allows trait and characterization data to be painted onto a pedigree tree. This tool won the best paper award at BioVis 2014 in Boston, USA. A freely available video and a presentation demonstrate the use of this program.
{kind=link}
For more information please contact us at: seed@masagro.org
Diversity Arrays Technology (DArT)
- To this date, DArT have analyzed approximately 400,000 DNA samples from almost 100 different species/crops for ca. 750 clients in more than 50 countries to generate data for a range of applications, including diversity analyses, QTL mapping, genomic selection, genetic-ID determinations, etc. DArTseq methods have so far been applied to approximately 50 different species/crops.
- The software-development group at DArT, in collaboration with colleagues at the Queensland Department of Energy and Water Supply, has been working for several years on a breeding-informatics platform (KDDart), which builds upon, and significantly expands, an older platform developed for plant variety trials and breeding applications (Katmandoo).
James Hutton Institute (JHI)
The bioinformatics group at the JHI has built several widely-used visualization software tools and databases, including Flapjack and Tablet for visualizing high-density genotypic and sequencing data, CurlyWhirly for visualizing genetic relationships in three dimensions, Strudel for aligning genetic maps, and Germinate for storing a wide variety of crop-related data. The Flapjack program, in particular, has been widely adopted in the next-generation sequencing community.
Features of the SeeDB platform
The SeeDB platform is being assembled from several carefully selected components, by (a) further developing existing software (GrinGlobal for genebank management, Germinate for data warehousing, and Flapjack, CurlyWhirly and Strudel for data visualization), (b) integrating components that are under active development (KDDart backend database for genotypic, phenotypic, environmental, GIS and seed/DNA inventory data, KDSmart for field-data acquisition on handhelds, and the IB Fieldbook interface for nursery and field-trial management), and (c) building new modules such as a non-relational database module for ultrahigh-throughput GBS data and new summarization, visualization and query tools for very large datasets.
A key element of the SeeDB platform is the Data-Access Layer (DAL) of the KDDart package. The web services-enabled DAL (currently version 2.0) communicates between backend databases and user interfaces tailored to specific applications and user groups. It will enable the modular “evolution” of system components going forward. Web services will be used to link the Maize and Wheat SeeD Catalogs to other online resources, for example the GeneSys portal, once they are web service-enabled as well.