








Miguel Borja Celio de CIMMYT captura datos de campo, utilizando software de la plataforma SeeDB en un dispositivo portátil. ©2012 (CIMMYT)
SeeD es posiblemente el esfuerzo más ambicioso de caracterización de bancos de germoplasma a nivel mundial hasta la fecha. El objetivo es caracterizar la estructura genética de hasta 200,000 muestras de ADN de accesiones de bancos de germoplasma y poblaciones/líneas pre-mejoradas. También caracterizaremos subconjuntos de muestras de diferentes tamaños y composiciones para caracteres priorizados por los programas de mejoramiento genético del maíz y el trigo.
Un proyecto tan ambicioso no sería posible sin una base sólida en dos tecnologías claves y facilitadoras:
- Una plataforma sólida y de alto rendimiento para generar perfiles genómicos que caractericen con precisión la diversidad genética desconocida. Esta plataforma debe permitir el análisis integral de muestras de diferentes bancos de germoplasma, genotipificadas en momentos diferentes; también debe basarse en métodos que son compatibles con futuras tecnologías de genotipificación.
- Una plataforma de software de vanguardia para recopilar, estandarizar, almacenar, consultar, visualizar y analizar el “tsunami” de datos que esperamos que generen los participantes del proyecto. Preferiblemente, esta plataforma debería constar de módulos que puedan ser reconfigurados para que los usuarios sean capaces de instalarlos ellos mismos a fin de utilizar más eficazmente los datos generados por el proyecto.

Científicos mexicanos jóvenes, capacitados durante seis meses cada uno, en tecnologías de genotipificación por secuenciación en DArT, Australia, antes de trabajar en SAGA. Desde el lado izquierdo hasta el derecho: Manuel Martínez, (Peter Wenzl, líder de SeeD), Hector Gálvez, Gerardo Gallegos y Aleyda Sierra. ©2012 (CIMMYT)
Dada la naturaleza crítica de estas tecnologías facilitadoras, hemos formado alianzas estratégicas con dos organizaciones que tienen un historial comprobado de entrega de soluciones que han sido rápidamente adoptadas por su clientela; Diversity Arrays Technology (DArT) y el grupo de bioinformática del Instituto James Hutton (JHI por sus siglas en inglés).
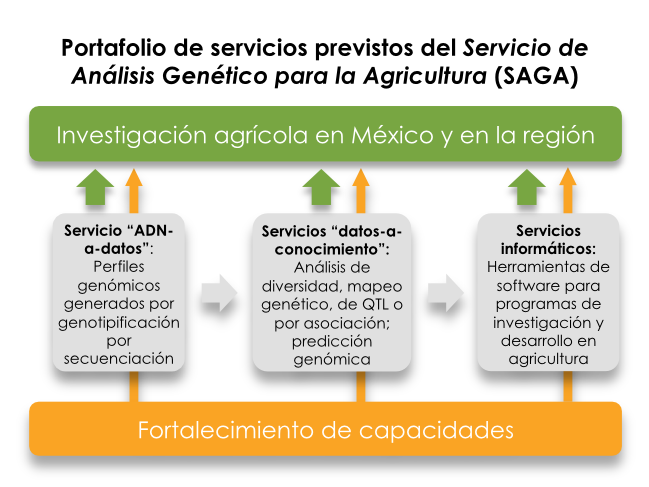
El objetivo principal de nuestra asociación con DArT es establecer y operar conjuntamente un Servicio de Análisis Genético para la Agricultura (SAGA) en el nuevo Centro Nacional de Recursos Genéticos (CNRG), ubicado en Tepatitlán, Jalisco. SAGA inicialmente se centrará en el análisis de muestras de ADN para SeeD y los otros componentes de MasAgro utilizando métodos de genotipificación por secuenciación (GBS), al mismo tiempo que servirá como un vehículo para el entrenamiento de científicos en el uso de datos moleculares para la investigación agrícola práctica. A mediano plazo, prevemos que las operaciones de SAGA se vuelvan autosuficientes, con el fin de seguir apoyando la investigación agrícola en México y en la región más allá de la duración del proyecto de SeeD, ofreciendo servicios de análisis genético y servicios de gestión de información y análisis de datos.
{kind=link}

Edificio para visitantes del Nuevo Centro Nacional de Recursos Genéticos (CNGR) en Tepatitlán, cerca de la ciudad de Guadalajara. El CNRG se ha convertido en el centro de recursos genéticos más grande de Latinoamérica. ©2012 (CIMMYT)
La gestión de la información representa un serio desafío para un proyecto como SeeD. Estamos trabajando con DArT y JHI con el objetivo de desarrollar conjuntamente una plataforma de software modular para el proyecto SeeD llamado ‘SeeDB‘ (‘base de datos de SeeD’).
La plataforma completa de SeeDB, incluyendo todos los componentes y módulos (por ejemplo, la colección de datos en campo) estará disponible de forma gratuita y el código será liberado bajo una licencia de código abierto a partir de la primera versión de producción.
Participantes en el proyecto han desarrollado algunos recursos que están disponibles al público que facilitan la visualización y análisis de datos.
| Resource | Provider | Functionality | Overview | Download |
| Flapjack | JHI | Genotypic data visualization | Overview | Download |
| CurlyWhirly | JHI | PCA analysis visualization | Overview | Download |
| Helium | JHI | Pedigree and characterization data visualization | Overview | Download |
| Strudel | JHI | Genetic and physical maps visualization | Overview | Download |
| Tablet | JHI | Next gen sequence data visualization | Overview | Download |
| Humbug | JHI | Barcode generation | Overview | Download |
| Germinate | JHI | Phenotypic, genotypic, climate, and passport data storage and visualization | Overview | Download |
| Germinate 3 Data Importer | JHI | Data import into Germinate 3 | Overview | Download |
| META-R – 3.5.1 | CIMMYT | R programs for statistical analyses relevant to breeding | Overview | Download |
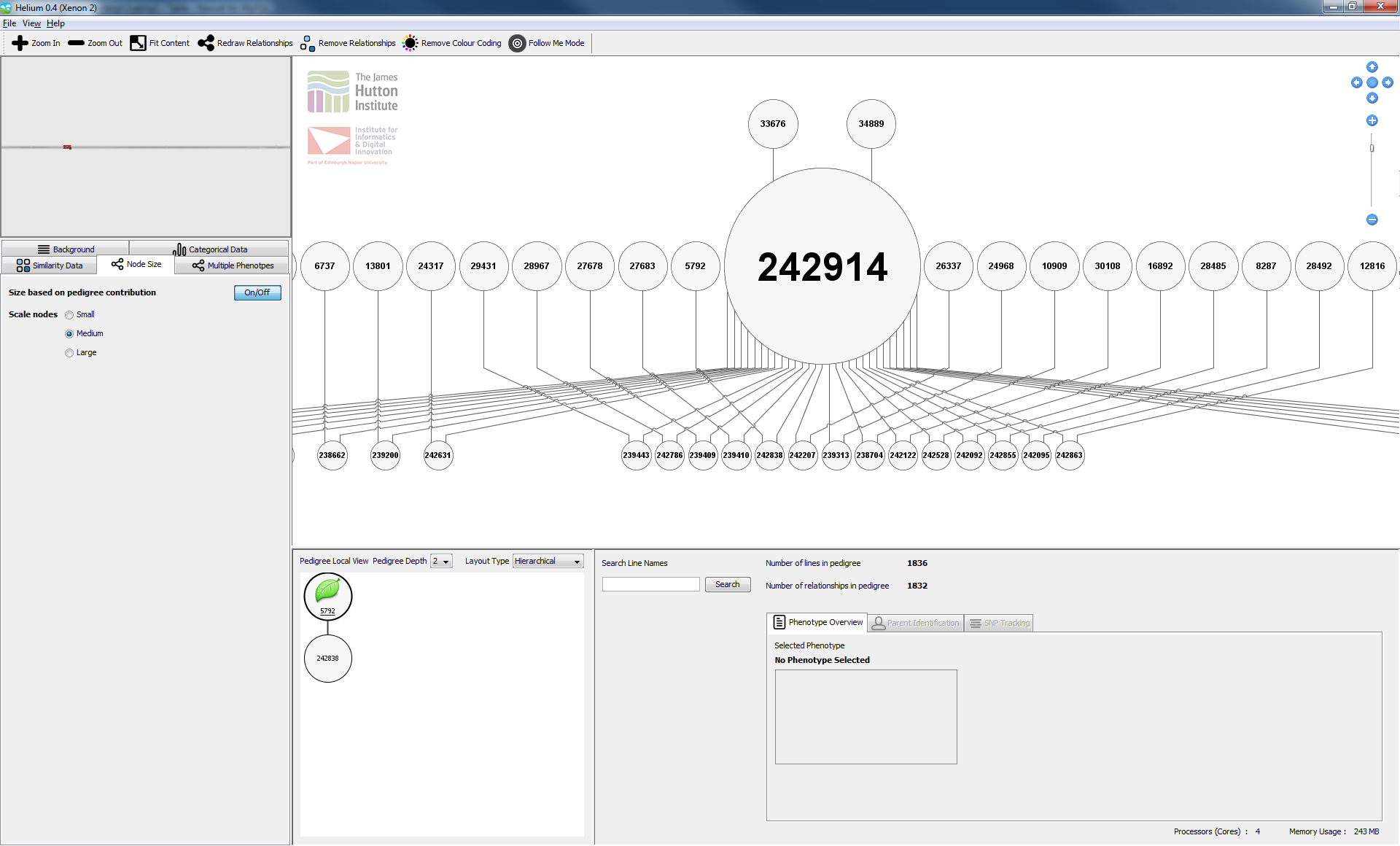
Helium es un ejemplo de una herramienta de visualización útil desarrollada por los colaboradores de SeeD que permite que los datos de rasgos y caracterización puedan ser ilustrados en un “árbol de pedigree.” Esta herramienta ganó el premio del mejor papel en la conferencia de BioVis 2014 en Boston en los EEUU. Aquí hay un video y una presentación disponibles que muestran el uso de este programa.
{kind=link}
Para obtener más información, escríbanos a: seed@masagro.org
Diversity Arrays Technology (DArT)
- Hasta la fecha, DArT ha analizado unas 400,000 muestras de ADN de casi 100 especies o cultivos distintos para 750 clientes en más de 50 países, generando datos para una amplia variedad de aplicaciones, incluyendo análisis de diversidad, mapeo de QTL, selección genómica, identificación genética de variedades, etc. Hasta ahora, se han aplicado métodos de genotipificación por secuenciación (GBS) a aproximadamente 50 especies o cultivos diferentes.
- El grupo de desarrollo de software en DArT, en colaboración con sus colegas en el Departamento de Suministro de Energía y Agua de Queensland, Australia, ha estado trabajando durante varios años en una plataforma de informática para mejoramiento genético (KDDart), que se basa en, y amplía significativamente, una plataforma más antigua desarrollada para ensayos de variedades de semilla y el mejoramiento genético (Katmandoo).
James Hutton Institute (JHI)
El grupo de bioinformática en JHI ha desarrollado varias herramientas de software de visualización y bases de datos ampliamente utilizadas, incluyendo Flapjack y Tablet para la visualización de datos genotípicos y de secuenciación de alta densidad, CurlyWhirly para visualizar relaciones genéticas en tres dimensiones, Strudel para el alineamiento de mapas genéticos y Germinate para almacenar una amplia variedad de datos relacionados con variedades de cultivos. El programa de Flapjack, en particular, ha sido ampliamente adoptado en la comunidad de secuenciación de la siguiente generación.
Características de la plataforma SeeDB
La plataforma SeeDB se está construyendo a partir de los siguientes componentes cuidadosamente seleccionados: (a) continuando el desarrollo de elementos de software existentes (GrinGlobal para administración de bancos de germoplasma y Germinate como almacén de datos; Flapjack, CurlyWhirly y Strudel para la visualización de datos), así como (b) integrando componentes que están bajo desarrollo activo (KDDart como base de datos “backend” para datos genotípicos, fenotípicos, ambientales y de información geográfica y datos de inventario para semillas y muestras de ADN; KDSmart para adquisición de datos de campo en dispositivos móviles; y la interface de IB Fieldbook para la administración de coensayos de campo) y (c) desarrollando nuevos módulos como una base de datos no-relacional para datos GBS de ultra alta-densidad y nuevas herramientas para resumir, visualizar y consultar conjuntos de datos muy grandes.
Un elemento clave de la plataforma SeeDB es la Capa de Acceso a Datos (DAL, por sus siglas en inglés) del paquete KDDart. La DAL (actualmente versión 2.0) ha sido habilitada para servicios web y comunica las bases de datos “backend” con las interfaces de usuario diseñadas para aplicaciones específicas, facilitando así el desarrollo modular a futuro de los diferentes componentes. Los servicios web se utilizarán para vincular el portal web de SeeD con otros recursos en línea, por ejemplo, el portal GeneSys, siempre y cuando éstos también ofrezcan servicios de web.